希尔排序算法
- 基本概念:希尔排序是插入排序的泛化版本,通过首先对间隔较远的元素排序,逐渐减少间隔距离,直到对相邻元素进行排序。
- 间隔序列:希尔排序性能依赖于选用的间隔序列,常见的有Shell、Knuth、Sedgewick、Hibbard等序列,不同序列��会影响排序效率。
- 复杂度与应用:希尔排序的时间复杂度在最好情况下为O(nlog n),最差情况下为O(n²),空间复杂度为O(1);适用于调用栈开销大、递归限制和元素距离较远情况。
希尔排序是插入排序算法的一种泛化版本。它首先对彼此间隔较远的元素进行排序,然后逐步减少要排序的元素之间的间隔。
元素之间的间隔根据使用的序列减少。在希尔排序算法中可以使用的一些最佳序列包括:
- Shell 的原始序列:
N/2, N/4,…, 1 - Knuth 的增量:
1, 4, 13,…, (3k – 1) / 2 - Sedgewick 的增量:
1, 8, 23, 77, 281, 1073, 4193, 16577...4j+1+ 3·2j+ 1 - Hibbard 的增量:
1, 3, 7, 15, 31, 63, 127, 255, 511… - Papernov & Stasevich 增量:
1, 3, 5, 9, 17, 33, 65,... - Pratt:
1, 2, 3, 4, 6, 9, 8, 12, 18, 27, 16, 24, 36, 54, 81....
**注意:**希尔排序的性能取决于用于给定输入数组的序列类型。
希尔排序的工作原理
-
假设我们需要排序以下数组。

-
我们在算法中使用了 shell 的原始序列
(N/2, N/4, ...1)作为间隔。在第一轮中,如果数组大小为
N = 8,那么间隔为N/2 = 4的元素将被比较并交换,如果它们不是有序的。 -
第
0个元素与第4个元素进行比较。 -
如果第
0个元素大于第4个,则首先将第4个元素存储在temp变量中,然后将第0个元素(即较大元素)存储在第4个位置,而存储在temp中的元素则存储在第0个位置。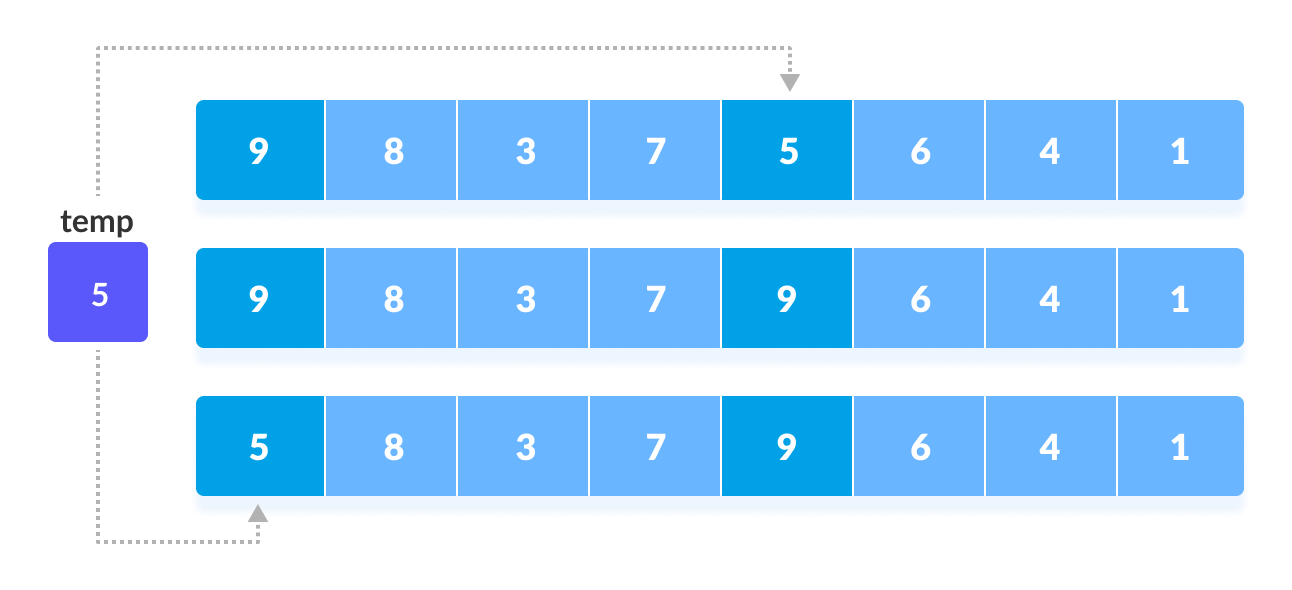
这个过程对所有剩余元素重复进行。
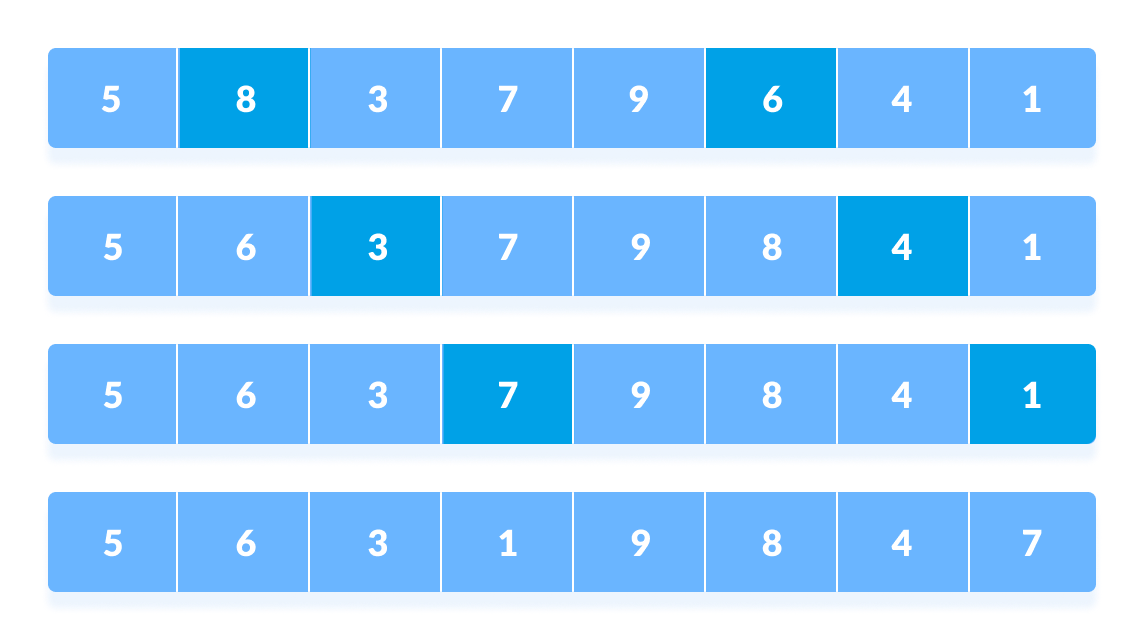
在第二轮中,取 N/4 = 8/4 = 2 的间隔,然后再次对这些间隔的元素进行排序。
在这一点上,你可能会感到困惑。
比较第 4 个和第 2 个位置的元素。也比较第 2 个和第 0 个位置的元素。数组中当前间隔处的所有元素都进行比较。
对剩余元素执行相同的过程。
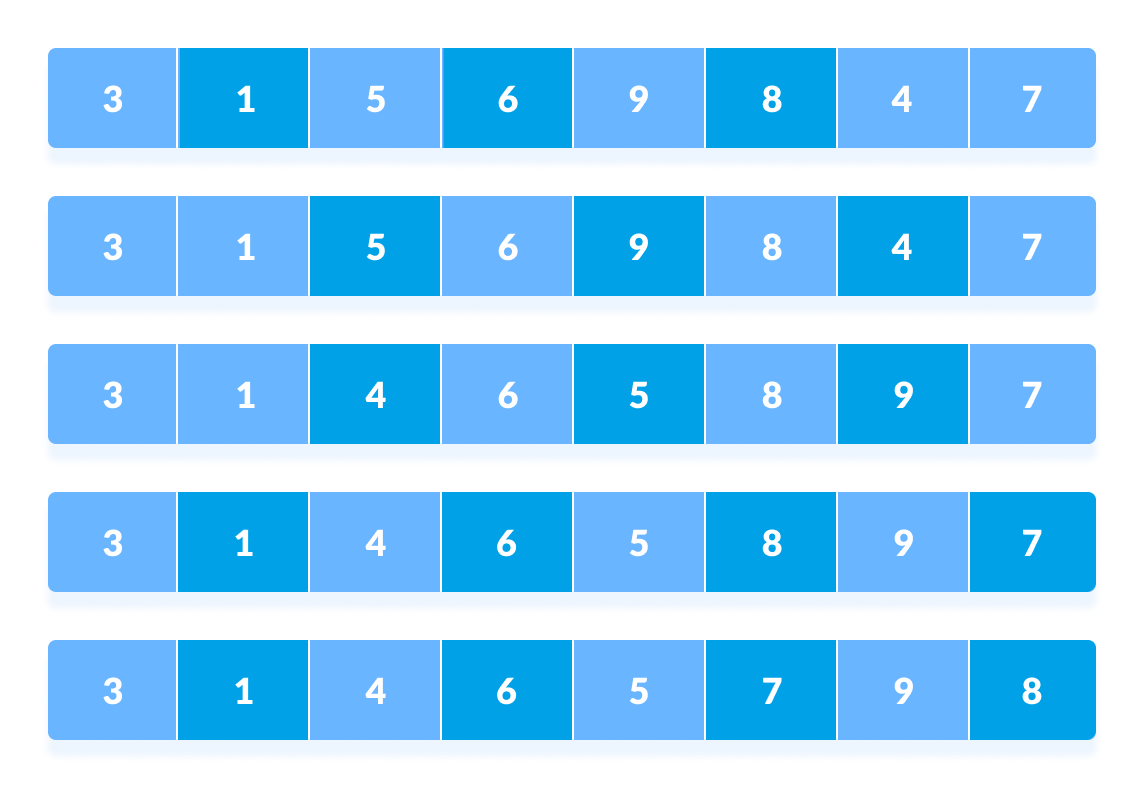
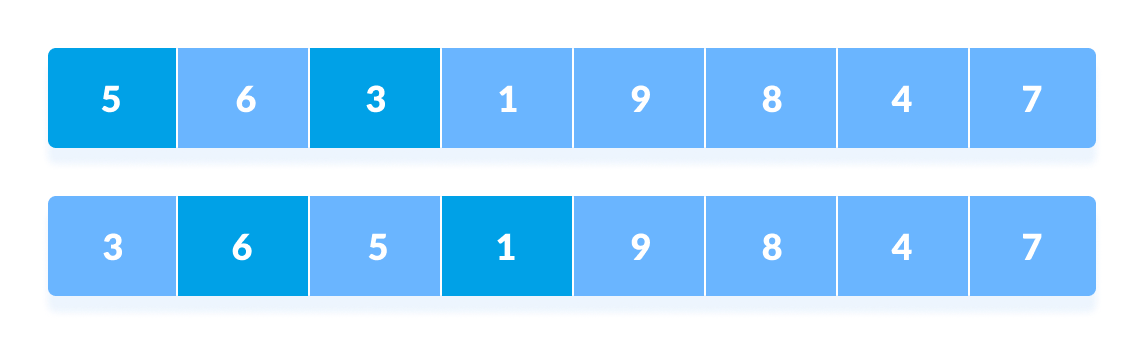
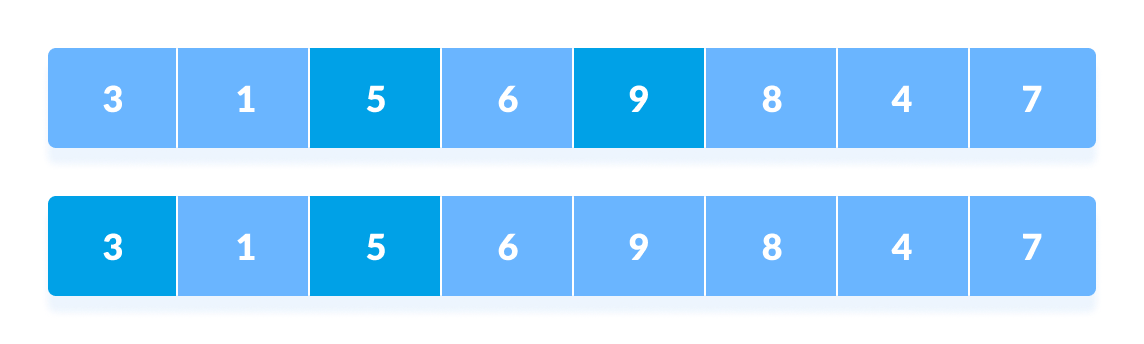
最后,当间隔为 N/8 = 8/8 =1 时,间隔为 1 的数组元素进行排序。此时数组已完全排序。

希尔排序算法
shellSort(array, size)
对于间隔 i <- size/2n 到 1
在数组中的每个间隔 "i"
对所有间隔为 "i" 的元素进行排序
end shellSort
Python、Java 和 C/C++ 中的希尔排序代码
# Python 中的希尔排序
def shellSort(array, n):
# 以 n/2, n/4, n/8, ... 为间隔重新排列元素
interval = n // 2
while interval > 0:
for i in range(interval, n):
temp = array[i]
j = i
while j >= interval and array[j - interval] > temp:
array[j] = array[j - interval]
j -= interval
array[j] = temp
interval //= 2
data = [9, 8, 3, 7, 5, 6, 4, 1]
size = len(data)
shellSort(data, size)
print('按升序排列的数组:')
print(data)
希尔排序的 Java 实现
import java.util.Arrays;
// 希尔排序
class ShellSort {
// 以 n/2, n/4, n/8, ... 为间隔重新排列元素
void shellSort(int array[], int n) {
for (int interval = n / 2; interval > 0; interval /= 2) {
for (int i = interval; i < n; i += 1) {
int temp = array[i];
int j;
for (j = i; j >= interval && array[j - interval] > temp; j -= interval) {
array[j] = array[j - interval];
}
array[j] = temp;
}
}
}
// 主函数
public static void main(String args[]) {
int[] data = { 9, 8, 3, 7, 5, 6, 4, 1 };
int size = data.length;
ShellSort ss = new ShellSort();
ss.shellSort(data, size);
System.out.println("升序排列的数组: ");
System.out.println(Arrays.toString(data));
}
}
希尔排序的 C 语言实现
#include <stdio.h>
// 希尔排序
void shellSort(int array[], int n) {
// 以 n/2, n/4, n/8, ... 为间隔重新排列元素
for (int interval = n / 2; interval > 0; interval /= 2) {
for (int i = interval; i < n; i += 1) {
int temp = array[i];
int j;
for (j = i; j >= interval && array[j - interval] > temp; j -= interval) {
array[j] = array[j - interval];
}
array[j] = temp;
}
}
}
// 打印数组
void printArray(int array[], int size) {
for (int i = 0; i < size; ++i) {
printf("%d ", array[i]);
}
printf("\n");
}
// 主函数
int main() {
int data[] = {9, 8, 3, 7, 5, 6, 4, 1};
int size = sizeof(data) / sizeof(data[0]);
shellSort(data, size);
printf("排序后的数组: \n");
printArray(data, size);
}
希尔排序的 C++ 实现
#include <iostream>
using namespace std;
// 希尔排序
void shellSort(int array[], int n) {
// 以 n/2, n/4, n/8, ... 为间隔重新排列元素
for (int interval = n / 2; interval > 0; interval /= 2) {
for (int i = interval; i < n; i += 1) {
int temp = array[i];
int j;
for (j = i; j >= interval && array[j - interval] > temp; j -= interval) {
array[j] = array[j - interval];
}
array[j] = temp;
}
}
}
// 打印数组
void printArray(int array[], int size) {
for (int i = 0; i < size; i++)
cout << array[i] << " ";
cout << endl;
}
// 主函数
int main() {
int data[] = {9, 8, 3, 7, 5, 6, 4, 1};
int size = sizeof(data) / sizeof(data[0]);
shellSort(data, size);
cout << "排序后的数组: \n";
printArray(data, size);
}
希尔排序的复杂度
| 时间复杂度 | |
|---|---|
| 最佳 | O(nlog n) |
| 最差 | O(n2) |
| 平均 | O(nlog n) |
| 空间复杂度 | O(1) |
| --- | --- |
| 稳定性 | 否 |
| --- | --- |
希尔排序是一种不稳定的排序算法,因为这种算法不检查间隔之间的元素。
时间复杂度
-
最差情况复杂度:小于或等于
O(n2)希尔排序的最差情况复杂度总是小于或等于O(n2)。根据 Poonen 定理,希尔排序的最差情况复杂度为
Θ(Nlog N)2/(log log N)2)或Θ(Nlog N)2/log log N)或Θ(N(log N)2)或介于两者之间。 -
最佳情况复杂度:
O(n*log n)当数组已经排序时,每个间隔(或增量)的总比较次数等于数组的大小。 -
平均情况复杂度:
O(n*log n)大约为O(n1.25)。
复杂度取决于选择的间隔。上述复杂度对于不同的增量序列是不同的。最佳增量序列尚未知晓。
空间复杂度:
希尔排序的空间复杂度为 O(1)。
希尔排序的应用
希尔排序适用于以下情况:
- 调用栈时开销较大。
uClibc库使用这种排序。 - 递归超过限制时。
bzip2压缩器使用它。 - 当相近元素距离较远时,插入排序表现不佳。希尔排序有助于减少相近元素之间的距离。因此,需要执行的交换次数将减少。