树形数据结构
提示
- 非线性数据结构:树是一种非线性层次化数据结构,由节点组成,通过边相互连接,与线性数据结构(如数组、链表)相比,树结构提供了更高效的数据存取方式。
- 树的基本术语:树包含了多个节点和边,其中每个节点可以有零个或多个子节点。树顶部的节点称为根节点,没有子节点的节点称为叶节点,其他节点称为内部节点。树的高度是从根到最深叶子的距离。
- 应用场景:树形数据结构广泛应用于各种场合,如二叉搜索树用于高效数据搜索,堆用于排序,Tries用于路由器中存储路由信息,数据库中使用B树存储数据,编译器使用语法树检查程序语法等。
树是一种非线性层次化的数据结构,由节点通过边连接而成。
为什么使用树形数据结构?
其他如数组、链表、栈和队列等线性数据结构按顺序存储数据。在线性数据结构中执行任何操作时,随着数据大小的增加,时间复杂度也会增加。但在当今的计算世界中,这是不可接受的。
不同的树形数据结构允许更快、更容易地访问数据,因为它是一种非线性数据结构。
树的术语
节点
节点是包含键或值以及指向其子节点的指针的实体。
每条路径的最后节点被称为叶节点或外部节点,不包含指向子节点的链接/指针。
至少有一个子节点的节点称为内部节点。
边
它是任意两个节点之间的链接。
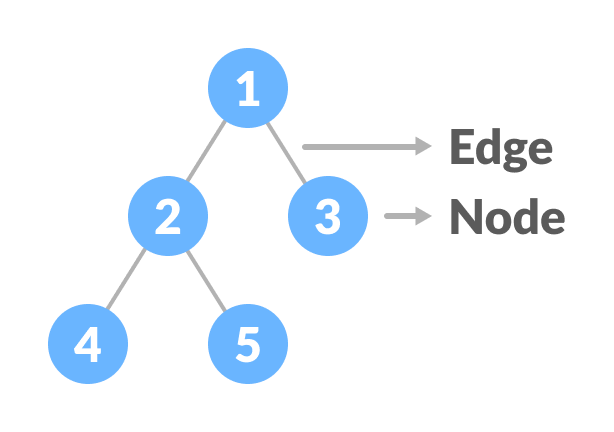
根
它是树的最顶部节点。
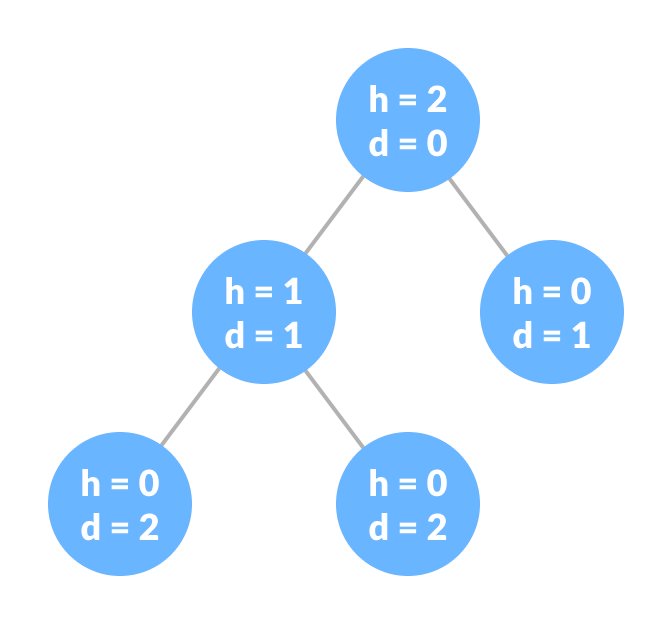
节点的高度
节点的高度是从该节点到最深叶子的边数(即从节点到叶节点的最长路径)。
节点的深度
节点的深度是从根到该节点的边数。
树的高度
树的高度是根节点的高度或最深节点的深度。
节点的度
节点的度是该节点的分支总数。
森林
不相交树的集合称为森林。
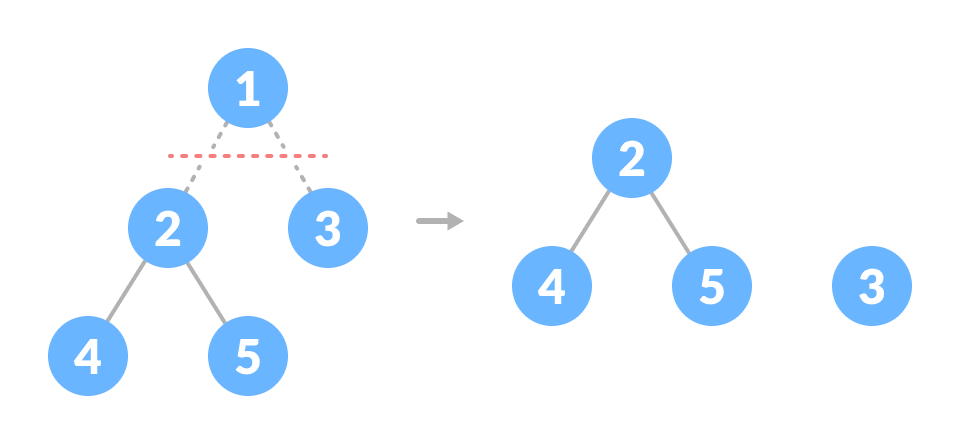
你可以通过切断树的根来创建一个森林。
树的类型
树的遍历
为了在树上执行任何操作,你需要到达特定的节点。树遍历算法有助于访问树中所需的节点。
要了解更多,请访问树的遍历。
树的应用
- 二叉搜索树(BST)用于快速检查元素是否存在于一个集合中。
- 堆是一种用于堆排序的树形结构。
- 在现代路由器中使用了树的修改版本 Tries 来存储路由信息。
- 大多数流行的数据库使用 B 树和 T 树(树结构的变体)来存储它们的数据。
- 编译器使用语法树来验证你编写的每个程序的语法。